Zero trust homelab V2
6 min read
Motivation
In an earlier post I described my homelab: a single EC2 instance running a small k3s cluster, with zero open ports to the public internet while still allowing secure remote access and selective app exposure. Here’s a quick recap:
- A single EC2 instance inside an Auto Scaling Group so the instance can be recreated in another AZ if it fails.
- A security group that blocks all ingress while allowing outbound traffic.
- A lightweight k3s cluster hosting my applications.
- The instance is part of my Tailscale network, so I can securely access it without exposing ports.
- cloudflared runs on the cluster to expose web apps through Cloudflare Tunnel — again, with zero open ports.
- CloudnativePG provides Postgres on the cluster, with daily backups so I can restore after a VM recreation (RDS is a bit expensive for a homelab).
- Metrics and logs are handled by Grafana Cloud: managed Prometheus for metrics and Loki for logs.
The overall design worked well, but a few pain points motivated a rethink:
- I managed both infrastructure and Kubernetes using Terraform. While Terraform is great for AWS resources, Grafana Cloud stacks, and DNS, it’s awkward for Kubernetes manifests and Helm charts. I split the work into two Terraform workspaces: one for infra (AWS, DNS, secrets) and one that consumed outputs from the first to render Helm/cluster resources. That caused friction: because my k3s cluster isn’t reachable except via Tailscale, Terraform Cloud’s remote runners couldn’t access it. My workaround was to run plans and applies locally — temporarily adding a GitHub Actions runner to my Tailscale network (there’s a helpful action for that) and performing the Terraform operations from that runner.
- When the VM got recreated the k3s state was lost and I often had to re-run the k3s workspace manually. The usual workaround was to change something in the infra workspace so that the second workspace would be triggered — not robust. Additionally, managing Helm charts through Terraform has known pitfalls, especially when updating existing charts or forcing rollouts.
Those limitations pushed me to find a more robust, maintainable approach.
New setup
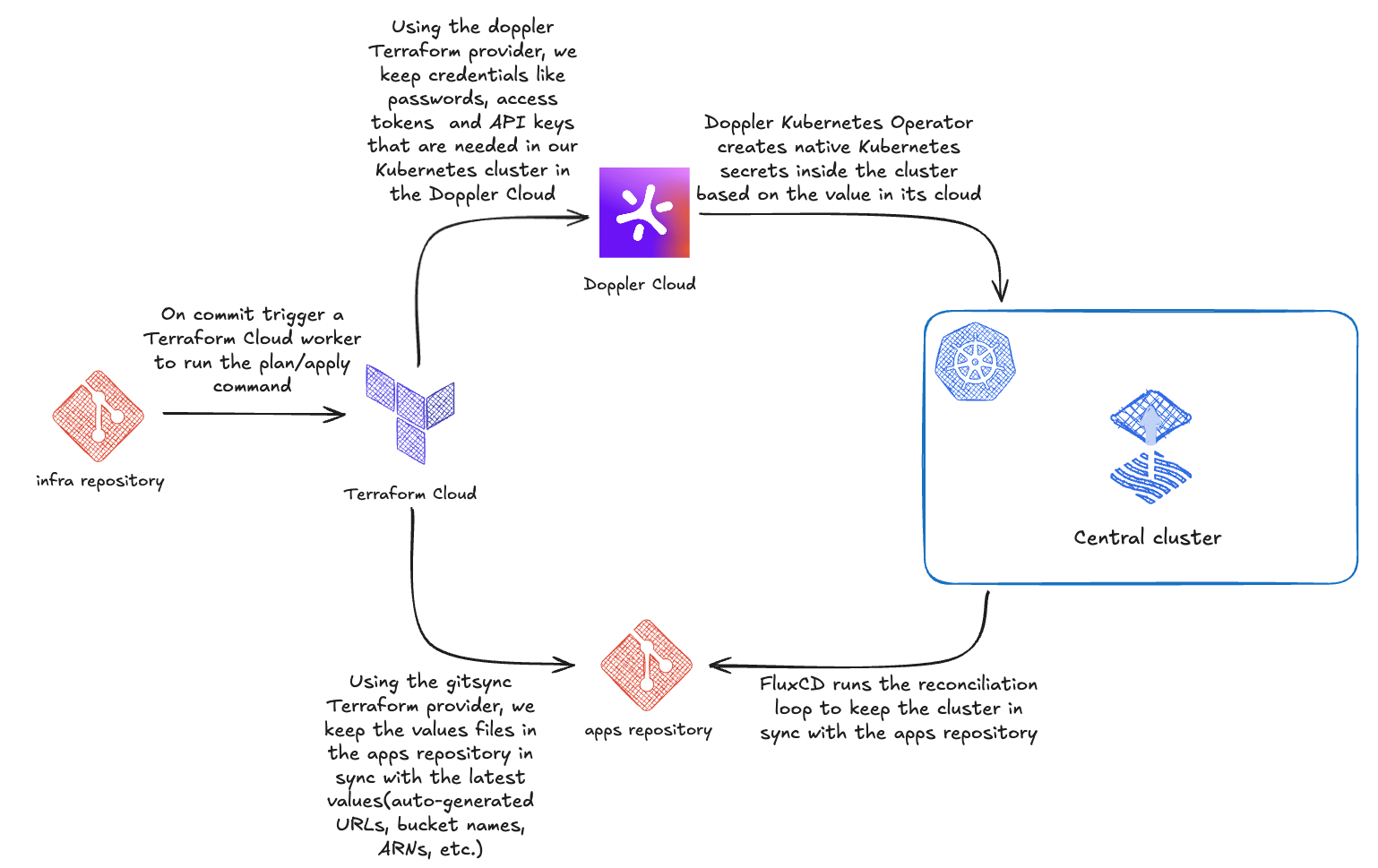
My plan was to adopt GitOps with FluxCD to manage the cluster. Flux is lightweight compared to ArgoCD and a natural fit for managing Kubernetes resources and Helm charts from Git. With values.yaml checked into Git, you get a clean, reusable setup and straightforward configuration for each app.
The main challenges I faced were:
- How to get non-sensitive values (DNS names, ARNs, etc.) produced by Terraform into the values.yaml files that FluxCD reads.
- How to inject sensitive values (database passwords, tunnel token, API keys, etc.) from Terraform into Kubernetes secrets securely.
I keep secrets in Terraform Cloud for convenience and to access auto-generated outputs (for example, DNS records). I looked for a clean way to get those values into Git-managed values.yaml files and to deliver sensitive values into Kubernetes without exposing them in Git. The solution I built has two pieces:
1) A small Terraform provider( ip812/gitsync) that syncs value files in a Git repo — it updates values.yaml with non-sensitive outputs from Terraform so FluxCD can pick them up and reconcile the cluster.
resource "gitsync_values_yaml" "go-template" {
branch = "main"
path = "values/${local.go_template_app_name}.yaml"
content = <<EOT
isInit: false
name: "${local.go_template_app_name}"
image: "ghcr.io/iypetrov/go-template:1.15.0"
hostname: "${cloudflare_dns_record.go_template_dns_record.name}"
replicas: 1
minMemory: "64Mi"
maxMemory: "128Mi"
minCPU: "50m"
maxCPU: "100m"
healthCheckEndpoint: "/healthz"
env:
- name: APP_ENV
value: "${local.env}"
- name: APP_DOMAIN
value: "${cloudflare_dns_record.go_template_dns_record.name}"
- name: APP_PORT
value: "8080"
- name: DB_NAME
value: "${local.go_template_db_name}"
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: "${local.go_template_app_name}-creds"
key: PG_USERNAME
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: "${local.go_template_app_name}-creds"
key: PG_PASSWORD
- name: DB_ENDPOINT
value: "${local.go_template_db_name}-pg-rw.${local.go_template_app_name}.svc.cluster.local"
- name: DB_SSL_MODE
value: disable
database:
postgres:
name: "${local.go_template_db_name}"
host: "${local.go_template_db_name}-pg-rw.${local.go_template_app_name}.svc.cluster.local"
image: "ghcr.io/cloudnative-pg/postgresql:16.1"
username: "${var.pg_username}"
storageSize: "1Gi"
retentionPolicy: "7d"
backupsBucket: "${aws_s3_bucket.pg_backups.bucket}"
backupSchedule: "0 0 0 * * *"
EOT
}The important part is that sensitive values are not stored in the committed values.yaml — instead, they are referenced from Kubernetes secrets by name.
2) For secret management I chose Doppler. HashiCorp Vault Dedicated is far too expensive for a hobby project(at the time of writing ~457$ per month), while Doppler offers a generous free tier plus good Terraform and Kubernetes integrations. Creating a secret in Doppler looks like this:
resource "doppler_secret" "pg_password" {
project = "prod"
config = "prd"
name = "PG_PASSWORD"
value = var.pg_password
}From Doppler I generate Kubernetes secrets (the Doppler Kubernetes operator supports processors to transform key names if necessary). Example:
---
apiVersion: secrets.doppler.com/v1alpha1
kind: DopplerSecret
metadata:
name: ghcr-auth-go-template
namespace: doppler-operator-system
spec:
tokenSecret:
name: doppler-token-secret
project: prod
config: prd
managedSecret:
name: ghcr-auth
namespace: go-template
type: kubernetes.io/dockerconfigjson
processors:
GHCR_DOCKERCONFIGJSON:
type: plain
asName: .dockerconfigjsonWith this setup the infra repository (Terraform) owns the source of truth for infrastructure and secrets. When Terraform produces values that should land in the cluster, the gitsync provider writes non-sensitive values into the values.yaml files in Git (Flux picks them up). Sensitive values live in Doppler and are projected into Kubernetes secrets via the Doppler operator. FluxCD reconciles the cluster from the Git repo, and Kubernetes pulls secrets from Doppler — no secrets committed to Git and no awkward Terraform workspace choreography.
I consider this my final GitOps-driven iteration for the homelab: a blend of Terraform for infra, FluxCD for cluster reconciliation, a small gitsync bridge for non-sensitive outputs, and Doppler for secrets. The result is simpler, more reliable, and easier to manage — and the approach scales beyond homelabs to production environments.
If you have questions or suggestions, jump into the comments or find me on social media. The infra repo is available here and the apps repo is here.